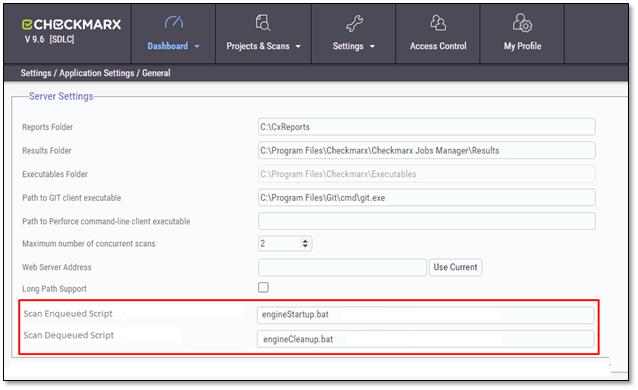
Scan Enqueued/ Dequeued Custom Scripts (for Dynamic Engines)
Overview
Instead of expensive and sluggish preconfigured engines, cut costs by 25%-50% and optimize resource usage with dynamic engine allocation, management, and deallocation in containerized environments. One of the major features of dynamic engine allocation is custom scripts for queued scans.
One of the processes the Scans Manager can initiate using custom scripts is the On-Demand Engine Startup feature. This feature allows you to visualize an engine image when a scan enters a Queued state and configure it using the desired Orchestrator (like K8S or Docker), enabling you to maintain a fixed list of registered Engines that handle your available scans. However, dedicated Dynamic Engines can be started to handle those pending scans during peak periods or when there is a backlog of scans in the queue.
The startup script receives specific arguments required for initializing and running the engine image.
These arguments include the scan ID, location, access control URL, message queue type, active message queue URL, message queue username, and message queue password. Once the engine finishes loading and initializing, it registers itself and becomes available to receive its dedicated scan as part of the Dedicated Engine feature.
After a scan has been completed, failed, or canceled, the Scans Manager executes a cleanup script provided and controlled by you. The cleanup script receives arguments such as the scan ID and the full engine URL.
This script signals the Orchestrator to terminate the engine and remove any potential zombie containers that might have been created during the scan process.
The startup and cleanup scripts have a built-in retry mechanism to ensure reliability and error handling. After an initial failure, the scripts are retried after a 30-second interval, with three attempts. The scripts are designed to handle errors returned by the scripts or errors that occur while running them. In cases where the script returns a specific error code indicating a terminating error, the scan is marked as failed and displays a message stating: Script failed. Further retries are not initiated in such cases. It is important to note that the script execution time is limited to 30 seconds. If a script exceeds this time limit, it is considered a failure and proceeds to the next retry attempt.
Note
The containerized environment might have some memory limitations per pod; if you handle a large project scan with a dedicated, always-on engine, configure the engine to handle all scans with a specific LOC range. The On-Demand Engine Startup script will run, but it should know when to exit and not run the engine for the scan (based on its LOC). Per the regular Scan Manager flow, the scan should automatically be assigned to the dedicated large projects engine.